Reading Records
该文篇幅不限,随笔记录日常网页浏览、算法理解等相关技术知识,以此作为以后回顾方便查询之依据,内容格式未做精细排版,标题名目无规则之限。
1. AI Models
-
Llama:
* 测试地址:https://llama-2.replit.app/ * 项目地址:https://github.com/facebookresearch/llama * 快速部署:https://github.com/mlc-ai/mlc-llm -
Qwen:
* 7B Train: https://modelscope.cn/models/qwen/Qwen-7B/summary * 7B Chat: https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary -
ModelScope:
* https://modelscope.cn * ModelScopeGPT:https://modelscope.cn/studios/damo/ModelScopeGPT/summary -
万物识别:
* https://modelscope.cn/models/damo/cv_resnest101_general_recognition/summary -
Gradio:
* 快速构建交互式网页 * Getting Started: https://www.gradio.app/guides/quickstart * hugging face token:https://huggingface.co/settings/tokens -
语音合成:
* https://modelscope.cn/models/damo/speech_sambert-hifigan_tts_zhiyan_emo_zh-cn_16k/summary -
MindChat:
* https://modelscope.cn/models/X-D-Lab/MindChat-Qwen-7B/summary -
Stable Diffusion XL:
* https://modelscope.cn/studios/AI-ModelScope/Stable_Diffusion_XL_1.0/summary -
车道线检测:
* https://modelscope.cn/models/damo/cv_yolopv2_image-driving-perception_bdd100k/summary -
基于gpt的图表生成:
* https://www.chartgpt.dev/ -
漫画上色:
* https://petalica.com/index_zh.html
2. SLAM
-
Stereo Ptam
https://github.com/uoip/stereo_ptam -
Visual Odometry
https://github.com/Transportation-Inspection/visual_odometry -
PythonRobtics
https://github.com/AtsushiSakai/PythonRobotics-
https://www.sohu.com/a/302914754_355123
- https://mp.weixin.qq.com/s?__biz=MzU1NjEwMTY0Mw==&mid=2247534757&idx=1&sn=28fb13c48e4c60da575827d877bb7e4a&chksm=fbc831c1ccbfb8d740c920eec8a80afdc767590a18f56613e7993f7e1e32d0a50afbc7e0add8&scene=27
- https://www.51cto.com/article/614590.html
-
3. Algorithm
-
3.1 DFS与BFS算法原理
深度优先遍历(Depth First Search, 简称 DFS) 与广度优先遍历(Breath First Search, 简称BFS)是图论中两种非常重要的算法,生产上广泛用于拓扑排序,寻路(走迷宫),搜索引擎,爬虫等,DFS的主要思路是从图中一个未访问的顶点 V 开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。
它的特点是不撞南墙不回头,先走完一条路,再换一条路继续走。而BFS是从图的一个未遍历的节点出发,先遍历这个节点的相邻节点,再依次遍历每个相邻节点的相邻节点。这是直观的原理。
-
3.1.1 DFS算法代码讲解
变量定义:
DFS算法所需要的变量包括
# start and goal position sx = 10.0 # [m] 起始位置x坐标 sy = 10.0 # [m] 起始位置y坐标 gx = 50.0 # [m] 目标点x坐标 gy = 50.0 # [m] 目标点y坐标 grid_size = 2.0 # [m] 网格的尺寸 robot_radius = 1.0 # [m] 机器人尺寸我们将地图(假设是方形)均匀地网格化,每一个网格代表一个点,同时每个点有一个序列号index变量来记录点的位置。
另外我们需要定义地图的边界min_x, min_y和max_x, max_y,用来计算遍历的点在地图中的序列号:
def calc_grid_position(self, index, minp): pos = index * self.reso + minp return pos其中minp指的就是min_x或者min_y,index是需要计算的节点的序列号,index乘以像素大小resolution(即我们前面定义的grid_size=2)得到x或者y方向的长度,这个长度值加在边界点min_x或者min_y上即可得到准确的坐标。
在遍历的过程中,我们需要定义
- open_set:路径规划过程中存放待检测的节点的集合
- closed_set: 存放已检测过的节点的集合
- motion: 在网状方格地图中,每个节点(边界点除外)周围有八个节点,对应八个方向,motion是固定存储前进方向的数组
def get_motion_model(): # dx, dy, cost: 每个数组中的三个元素分别表示向x,y方向前进的距离以及前进代价 motion = [[1, 0, 1], #右 [0, 1, 1], #上 [-1, 0, 1], #左 [0, -1, 1], #下 [-1, -1, math.sqrt(2)], #左下 [-1, 1, math.sqrt(2)], #左上 [1, -1, math.sqrt(2)], #右下 [1, 1, math.sqrt(2)]] #右上 return motion即在贪婪遍历时,会遍历周边八个点的cost以选出最小的cost。
函数定义:
在介绍完这些变量后,我们开始定义函数,首先是DFS的类,初始化网格地图:
def __init__(self, ox, oy, resolution, robot_radius): self.reso = reso self.rr = rr self.calc_obstacle_map(ox, oy) self.motion = self.get_motion_model()然后我们定义搜索区域节点(Node)的类
class Node: def __init__(self, x, y, cost, pind, parent): self.x = x # index of grid self.y = y # index of grid self.cost = cost self.pind = pind self.parent = paren每个Node都包含坐标x和y,代价cost和其父节点(上一个遍历的点),注意此处的pind是用来存放遍历过程中父节点的ID,在最后计算路径时从目标点往上回溯至起始位置。
在遍历时我们需要计算每个坐标的index
def calc_xy_index(self, position, minp): return round((position - minp) / self.resolution) def calc_grid_index(self, node): return (node.y - self.miny) * self.xwidth + (node.x - self.minx)同时还有另外两个函数,一个是验证节点的verify_node函数:判断节点的坐标在[min_x,max_x]和[min_y,max_y]的范围内,同时验证该节点不在障碍层;
另一个是用来计算障碍层地图的函数calc_obstacle_map,其中障碍物的点是我们在main函数中定义的。
规划函数:
在介绍完其他功能函数后,就是介绍最重要的规划函数,该函数定义在DepthFirstSearchPlanner类中,输入起始点和目标点的坐标(sx,sy)和(gx,gy),最终输出的结果是路径包含的点的坐标集合rx和ry。
首先根据起始点、目标点的输入坐标来定义Node类,同时初始化open set, closed set(为dict()类型),将起始点存放在open_set中:
nstart = self.Node(self.calc_xyindex(sx, self.minx), self.calc_xyindex(sy, self.miny), 0.0, -1, None) ngoal = self.Node(self.calc_xyindex(gx, self.minx), self.calc_xyindex(gy, self.miny), 0.0, -1, None) open_set, closed_set = dict(), dict() open_set[self.calc_grid_index(nstart)] = nstar然后在while循环中从起始点(sx,sy)开始遍历所有点寻找最优路径,直到找到目标点(gx,gy)后循环终止。
前面我们提到的贪婪遍历motion的函数,包括八个点,由于在我们的case中目标点在起始点的右上方,所以我们优先选取遍历点的最后一个子节点(即右上方的点)进行深度遍历
current = open_set.pop(list(open_set.keys())[-1]) c_id = self.calc_grid_index(current)其中[-1]则表示选取最后一个序号的子节点。在选取下一个要遍历的节点current后先通过动画画出这个点的位置(此处省略画图的代码),然后要判断是否其是目标点,如果是则遍历结束,break掉这个while循环
if current.x == ngoal.x and current.y == ngoal.y: print("Find goal") ngoal.pind = current.pind ngoal.cost = current.cost break随后就是根据motion模型的八个点进行贪婪遍历,如果遍历到的子节点不在closed_set中,则将其加入open_set和closed_set中对应的index里,同时更改这个点的父节点为current
for i, _ in enumerate(self.motion): node = self.Node(current.x + self.motion[i][0], current.y + self.motion[i][1], current.cost + self.motion[i][2], c_id, None) n_id = self.calc_grid_index(node) # If the node is not safe, do nothing if not self.verify_node(node): continue if n_id not in closed_set: open_set[n_id] = node closed_set[n_id] = node node.parent = current重复上述while循环过程直到current点为目标点。 最后,通过将目标点和closed set传入calc_final_path函数来产生最后的路径并结束while循环
rx, ry = self.calc_final_path(ngoal, closed_set) def calc_final_path(self, ngoal, closedset): # generate final course rx, ry = [self.calc_grid_position(ngoal.x, self.minx)], [ self.calc_grid_position(ngoal.y, self.miny)] n = closedset[ngoal.pind] while n is not None: rx.append(self.calc_grid_position(n.x, self.minx)) ry.append(self.calc_grid_position(n.y, self.miny)) n = n.parent return rx, ry这里的目标点就是首先通过ngoal.pind寻找到父节点(因为目标点没有被赋予父节点就停止遍历了),然后通过迭代父节点直到起始位置(父节点为空)即可停止,获取的rx,ry集合即位最终路径。
最后的main函数是定义起点和目标点、设置障碍物的位置、调用类以及里面的函数进行规划运算,并且动态展示出来运算结果。
-
3.1.2 BFS算法代码讲解:
BFS的变量和函数定义与DFS完全相同,其中不同的两点分别是:
-
从open_set中选取的遍历节点current方式不同,BFS优先选取的是两侧的节点(即注重广度),而DFS优先选取的是四角的节点(注重深度)。
-
BFS会在开始时便将current加入到closed_set中,并且只会将current的点加入到closed_set中,这样才能优先把同一层并列的其他节点遍历完,而DFS则会将current的所有子节点都加入到closed_set中,并且只选择其中的一个序号的子节点往下遍历,这样才能更快遍历到最深的层。
这两个地方的代码体现依次是:在while循环开始时定义current
current = open_set.pop(list(open_set.keys())[0]) c_id = self.calc_grid_index(current) closed_set[c_id] = current以及在根据motion模型贪婪遍历子节点时
for i, _ in enumerate(self.motion): node = self.Node(current.x + self.motion[i][0], current.y + self.motion[i][1], current.cost + self.motion[i][2], c_id, None) n_id = self.calc_grid_index(node) # If the node is not safe, do nothing if not self.verify_node(node): continue if (n_id not in closed_set) and (n_id not in open_set): node.parent = current open_set[n_id] = node -
-
3.1.3 远行结果:
-
DFS运行结果:
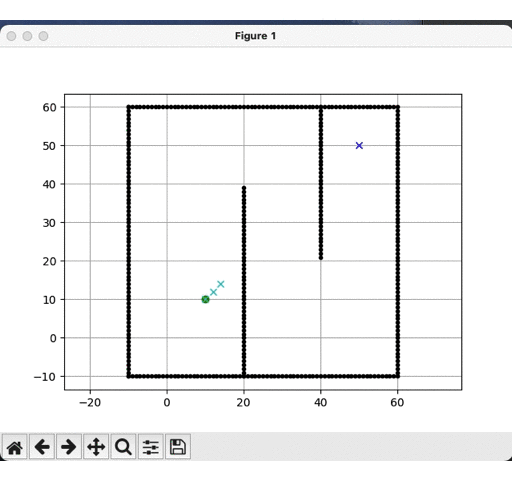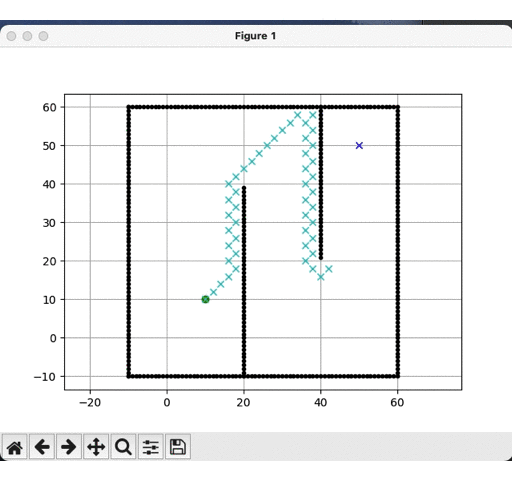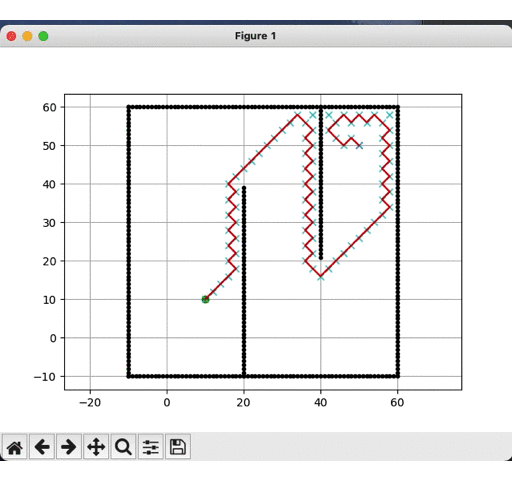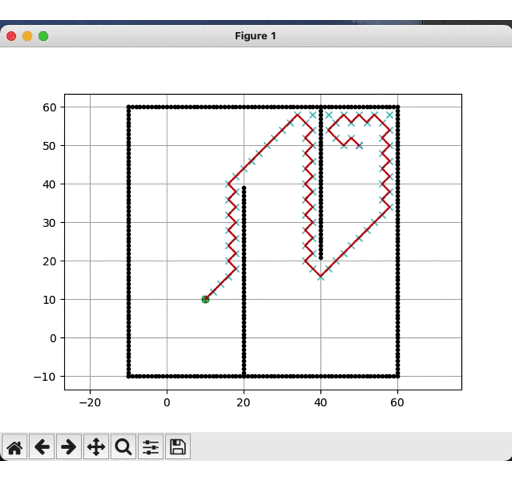
-
BFS运行结果:
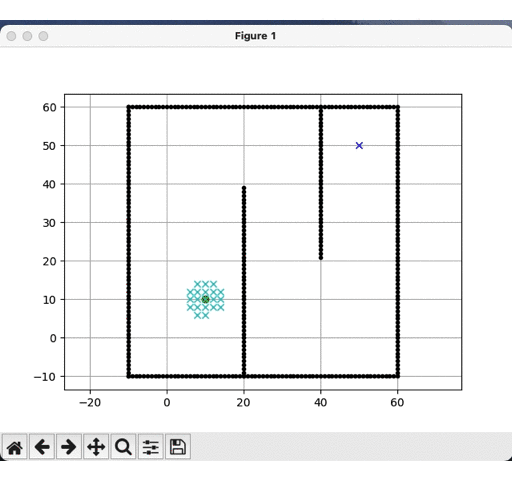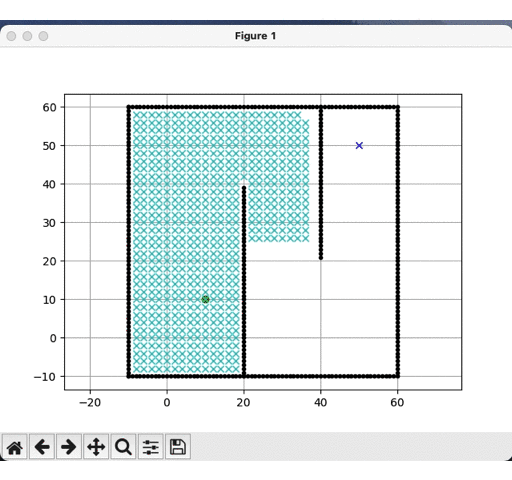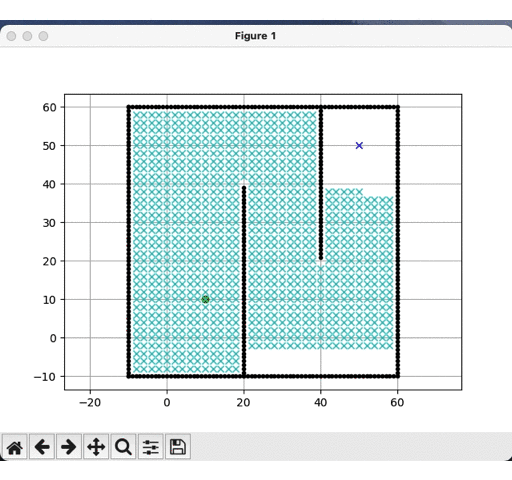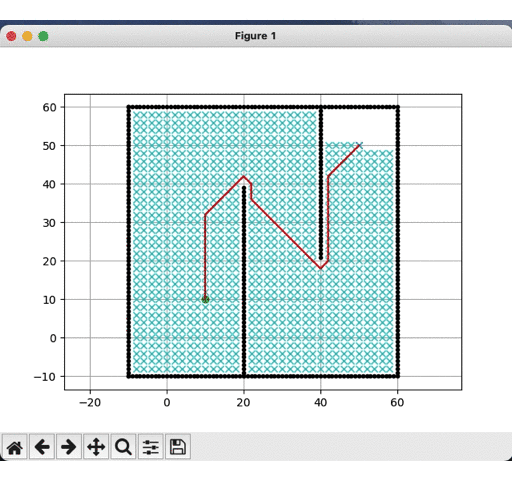
明显可见,深度优先更快到达目标点,而广度优先遍历的节点远多于深度优先,但是就结果而见,深度优先的路径并非是最优的,这是由计算时间换取的精度代价。
-
-