大语言模型之LLaMa2
llama2是meta最新开源的语言大模型,训练数据集2万亿token,上下文长度是由llama的2048扩展到4096,可以理解和生成更长的文本,包括7B、13B和70B三个模型,在各种基准集的测试上表现突出,最重要的是,该模型可用于研究和商业用途。
1. 基础知识
1.1 分词(tokenize)
语言模型是对文本进行推理。由于文本是字符串,但对模型来说,输入只能是数字,所以就需要将文本转成用数字来表达。最直接的想法,就是类似查字典,构造一个字典,包含文本中所有出现的词汇,比如中文,可以每个字作为词典的一个元素,构成一个列表;一个句子就可以转换成由每个词的编号(词在词典中的序号)组成的数字表达。
tokenize就是分词,一般分成3种粒度:
- word(词)
词是最简单的方式,例如英文可以按单词切分。缺点就是词汇表要包含所有词,词汇表比较大;还有比如“have”,”had”其实是有关系的,直接分词没有体现二者的关系;且容易产生oov问题(Out-Of-Vocabulary,出现没有见过的词)
- char(字符)
用基础字符表示,比如英文用26个字母表示。比如 “China”拆分为”C”,”h”,”i”,”n”,”a”,这样降低了内存和复杂度,但增加了任务的复杂度,一个字母没有任何语义意义,单纯使用字符可能导致模型性能的下降。
- subword(子词)
结合上述2个的优缺点,遵循“尽量不分解常用词,将不常用词分解为常用的子词”的原则。例如”unbelievable”在英文中是un+形容词的组合,表否定的意思,可以分解成un”+”believable”。通过这种形式,词汇量大小不会特别大,也能学到词的关系,同时还能缓解oov问题。
subword分词主要有BPE,WorkdPiece,Unigram等方法。
BPE:字节对编码,就是是从字母开始,不断在语料库中找词频最高、且连续的token合并,直到达到目标词数。具体细节可参考【Suprit:BPE 算法原理及使用指南【深入浅出】】。 WordPiece:WordPiece算法和BPE类似,区别在于WordPiece是基于概率生成新的subword而不是下一最高频字节对。 Unigram:它和 BPE 等一个不同就是,bpe是初始化一个小词表,然后一个个增加到限定的词汇量,而 Unigram 是先初始一个大词表,接着通过语言模型评估不断减少词表,直到限定词汇量。
具体可以参考【BPE、WordPiece和SentencePiece】和【Luke:深入理解NLP Subword算法:BPE、WordPiece、ULM】。
当然,现在已经有很多预训练好的词汇表,如果需要扩充新的语言,比如中文,可以先收集好语料库(训练文本),然后用SentencePiece训练自己的分词模型。具体可以看【GitHub - taishan1994/sentencepiece_chinese_bpe: 使用sentencepiece中BPE训练中文词表,并在transformers中进行使用】
1.2 embedding
经过分词,文本就可以分解成用数字表示的token序列。对于一个句子,最直接的表示法就是one-hot编码。假如词汇表【我,喜,欢,吃,面】,此时词汇大小(vocab_size)大小为5,那句子“我喜欢”用one-hot编码如下图。当词汇表特别大时(llama词汇大小是3万多),句子的向量(n*vocab_size)表示也就变的比较大;另外,“喜欢”这个词出现在一起的频率其实比较高,但one-hot编码也忽略了这个特性。

embedding就是将句子的向量表示压缩,具体就是词汇表的每个词映射到一个高维(d维)的特征空间。
# 一般embedding在语言模型的最开始,也就是词token操作之后
# vocab_size 词汇表大小,hidden_size 隐藏层维度大小
word_embeddings= nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
# input_ids是句子分词后词id,比如上述的“我喜欢”可转换成为[0,1,2],数字是在词汇表【我,喜,欢,吃,面】中的索引,即token id
embeddings = word_embeddings(input_ids) # embeddings的shape为[b,s,d],b:batch,s:seq_len,d:embedding size
embedding的每维特征都可以看出词的一个特征,比如人可以通过身高,体重,地址,年龄等多个特征表示,对于每个词embedding的每个维度的具体含义,不用人为定义,模型自己去学习。这样,在d维空间上,语义相近的词的向量就比较相似了,同时embedding还能起到降维的作用,将one-hot的[s,vocab_size]大小变成了[s,d]。
具体可参考【千寻:Embedding的作用】。
1.3 transformer
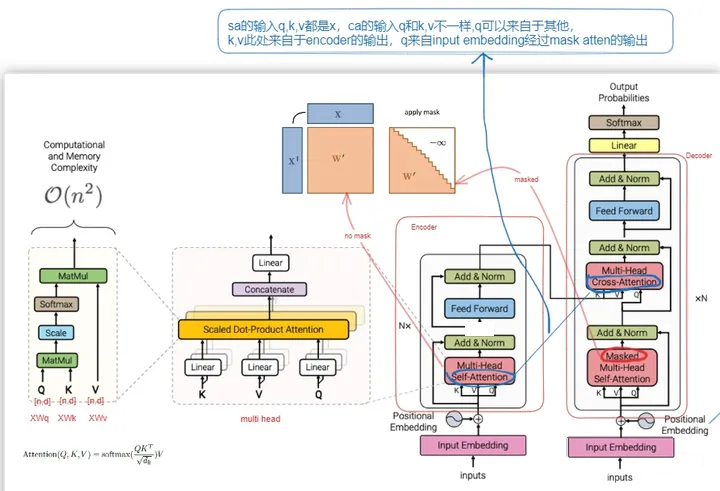
目前大语言模型都是基于transformer结构。
下图说明transformer的结构,第一张图代表transformer的结构,第二张图说明position embedding。
-
transformer结构
-
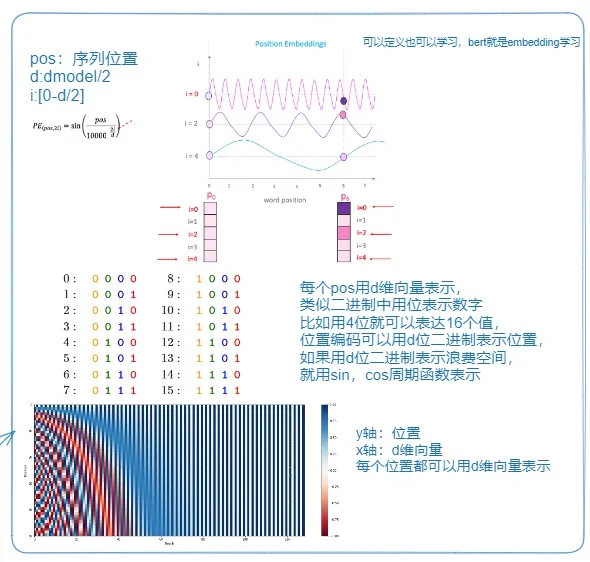
position embedding
具体transformer可以参考【初识CV:Transformer模型详解(图解最完整版)】。
position embeding可以参考【Transformer Architecture: The Positional Encoding】和【猛猿:Transformer学习笔记一:Positional Encoding(位置编码)】。
2. llama2模型
2.1 模型结构
从transformer的结构图可见,transformer可以分成2部分,encoder和decoder,而llama只用了tranformer的decoder部分,是decoder-only结构。目前大部分生成式的语言模型都是采用这种结构,bert采用Encoder-only,google t5采用encoder-decoder结构。
| 至于为什么用decoder-only,参考苏剑林【[为什么现在的LLM都是Decoder-only的架构? - 科学空间 | Scientific Spaces](https://link.zhihu.com/?target=https%3A//kexue.fm/archives/9529)】,其中提到了attention在n×d的矩阵与d×n的矩阵相乘后再加softmax(n≫d),这种形式的Attention的矩阵因为低秩问题而带来表达能力的下降,但decoder only因为用了masked attention,是一个下三角矩阵,attention一定是满秩的。也可以参考【CastellanZhang:【大模型慢学】GPT起源以及GPT系列采用Decoder-only架构的原因探讨】。 |
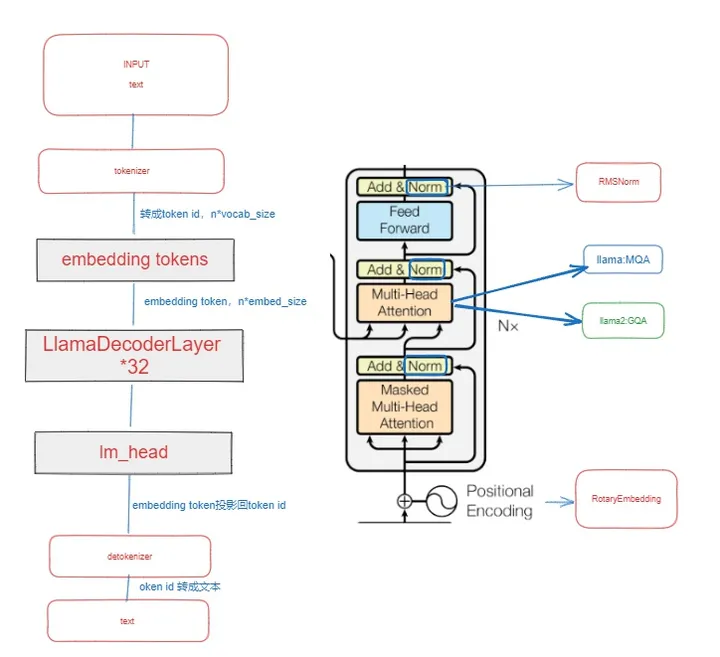
llama和llama2在模型结构了基本一致,llama2结构如下图左半部分,llama共用了32个Decoder层。
其中每个decoder层如下图右半部分所示,主要是将transformer中的LayerNorm换成了RMSNorm,Multi-Head Attention换成了GQA(llama是MQA),postionnal换成了RotatyEmbedding(RoPE相对位置编码)。
2.2 MHA/MQA/GAQ
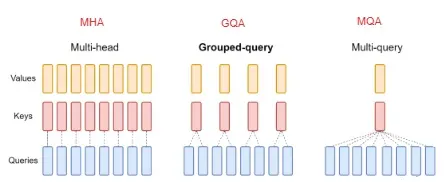
原始的 MHA(Multi-Head Attention),QKV 三部分有相同数量的头,且一一对应。每次做 Attention,head1 的 QKV 就做好自己运算就可以,输出时各个头加起来就行。
而 MQA 则是,让 Q 仍然保持原来的头数,但 K 和 V 只有一个头,相当于所有的 Q 头共享一组 K 和 V 头,所以叫做 Multi-Query 了。实验发现一般能提高 30%-40% 的吞吐,性能降低不太大。
GQA 综合MHA 和 MQA ,既不损失太多性能,又能利用 MQA 的推理加速。不是所有 Q 头共享一组 KV,而是分组一定头数 Q 共享一组 KV,比如上图中就是两组 Q 共享一组 KV。
具体可以参考【Andy Yang:为什么现在大家都在用 MQA 和 GQA?】
2.3 RoPE(相对位置编码)
起初,一般用绝对位置编码对token编码,【Taylor Wu:Transformer改进之相对位置编码(RPE)】中提到,绝对编码可能丢失了相对位置关系。
RoPE是利用绝对位置编码表示相对位置的一种方式,不仅保持位置编码,还能保持相对位置的关系。
将位置m转成β进制,构成一个d//2维的向量,用这个向量就能计算出位置。
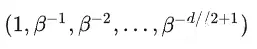
每维的数值映射到一个2*2d的矩阵,如下图所示:
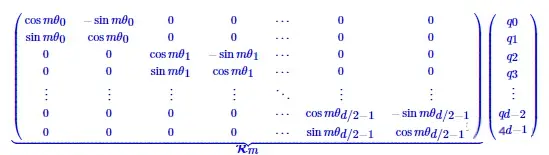
代码可以参考transformer库的modeling_llama.py中的LlamaRotaryEmbedding,rotate_half,apply_rotary_pos_emb。
| 详细讲解参考【[Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间 | Scientific Spaces](https://link.zhihu.com/?target=https%3A//spaces.ac.cn/archives/8265)】和【suc16:LLM学习记录(五)–超简单的RoPE理解方式】 |
2.4 RMSNorm
layerNorm公式,其中E[x]代表均值,Var[x]代表方差。
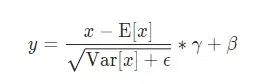
RMSNorm公式

对比RMSNorm和layerNorm,其实就是RMSNorm去掉了减去均值,简化了LayerNorm,减少了7%∼64%的计算时间。
3. 推理
3.1 generate接口
llama模型推理时和一般深度学习模型不同,重新封装了一个generate方法,推理参数参考代码。
input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids, # prompt,输入部分
"max_new_tokens":512, # 新生成的句子的token长度
"do_sample":True, # 是否采样,相当于每次不再是选择top k(beam num)个概率最大的,而是加了一些采样
"top_k":50,#在随机采样(random sampling)时,前top_k高概率的token将作为候选token被随机采样。
"top_p":0.95,#在随机采样(random sampling)时,累积概率超过top_p的token将作为候选token被随机采样,越低随机性越大,
举个例子,当top_p设定为0.6时,概率前5的token概率分别为[0.23, 0.20, 0.18, 0.11, 0.10]时,前三个token的累积概率为0.61,那么第4个token将被过滤掉,只有前三的token将作为候选token被随机采样。
"temperature":0.3, # 采样温度,较高的值如0.8会使输出更加随机,而较低的值如0.2则会使其输出更具有确定性
"num_beams":3, # 当搜索策略为束搜索(beam search)时,该参数为在束搜索(beam search)中所使用的束个数,当num_beams=1时,实际上就是贪心搜索(greedy decoding)
"repetition_penalty":1.3,#重复惩罚,
"eos_token_id":tokenizer.eos_token_id, # 结束token
"bos_token_id":tokenizer.bos_token_id, # 开始token
"pad_token_id":tokenizer.pad_token_id # pad的token
}
generate_ids = model.generate(**generate_input)
3.2 集束搜索(beam search)
在模型解码过程中,模型是根据前一个结果继续预测后边的,依次推理,此时为了生成完整的句子,需要融合多个step的输出,目标就是使得输出序列的每一步的条件概率相乘最大。
最直接的方法就是贪心算法(greedy search),每步取概率最大的输出,然后将从开始到当前步的输出作为输入,取预测下一步,直到句子结束。如下图所示,第一步先去概率最大的A,依次是B,C。这种的缺点就是如果中间某一步取值不对,将影响后续的结果。

beam search对贪心算法做了优化,在每个step取beam num个最优的tokens。下图beam num=2,第一步先选取最优的2个值{A,C};在第二步,A和C作为输入,继续预测,则有10个可能得结果,然后再取其中最大的2个,作为输入,进行第三步,取结果中概率最大的2个,得到2个结果,然后再在2个结果中取最优的一个作为输出。
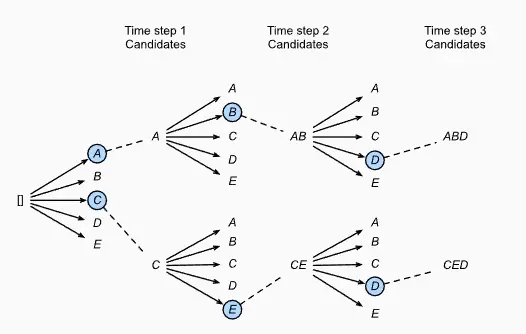
beam num=2,输出长度=3的情况
详细可参考【https://d2l.ai/chapter_recurrent-modern/beam-search.html】和【itachi:如何通俗的理解beam search?】
3.3 RoPE外推
llama1训练时token长度是2048,llama2虽然升级到了4096,但相比gpt-4的32K还是比较短,对于长文本的生成会有限制。
结合RoPE的特性,可以通过位置插值,扩展token的长度。最简单的方法就是线性插值,如下图所示:
对于下图的上半部分,对于2048之后的位置超出了训练2048的长度,模型推理时,该部分很可能就随机乱猜了,导致生成的结果不好。可以将超出的部分通过线性插值压缩到2048,这样只需要用少量4096长度的数据微调,就能达到很好的效果。
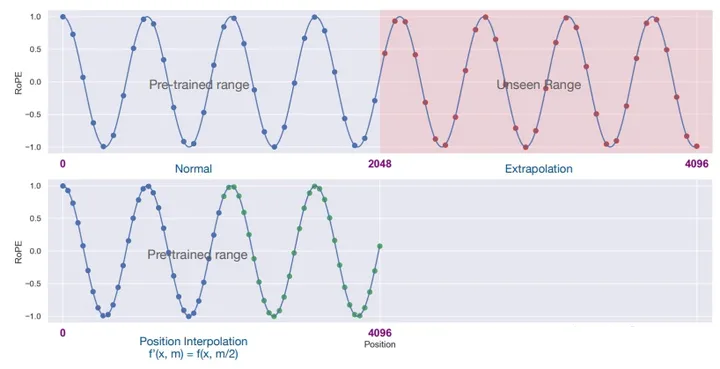
另外还有NTK和动态插值算法等,transformer的llama2中实现了LlamaLinearScalingRotaryEmbedding和LlamaDynamicNTKScalingRotaryEmbedding。
| 详细可参考【[Transformer升级之路:7、长度外推性与局部注意力 - 科学空间 | Scientific Spaces](https://link.zhihu.com/?target=https%3A//kexue.fm/archives/9431)】和【LinguaMind:浅谈LLM的长度外推】。 |
4. 训练
训练分为预训练、指令微调、奖励模型训练。
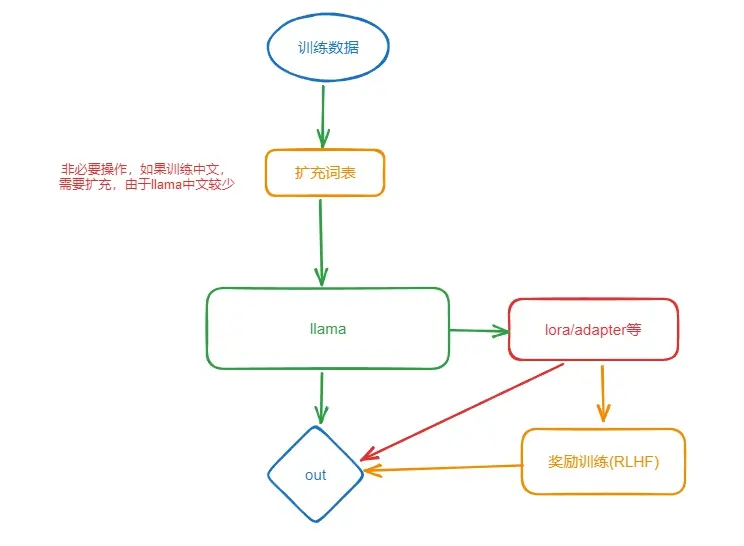
4.1 数据集
列出几个数据集。
- 【Awesome-Chinese-LLM中文数据集】
- 【awesome-instruction-dataset】
- 【awesome-instruction-datasets】
- 【LLaMA-Efficient-Tuning-数据集】
4.2 预训练
-
扩充词表
如果需要扩充词表,可以用sentencepiece训练新的词表。
具体可参考【GitHub - taishan1994/sentencepiece_chinese_bpe】
然后合并新的词表,参考代码【merge_tokenizers】。
-
预训练
主要参考2个库。
具体参考文档,支持单GPU训练。
2.Chinese-LLaMA-Alpaca-2-预训练脚本
支持多级多卡训练。
4.3 监督微调(sft)
分为参数高效微调和全部/部分参数微调。
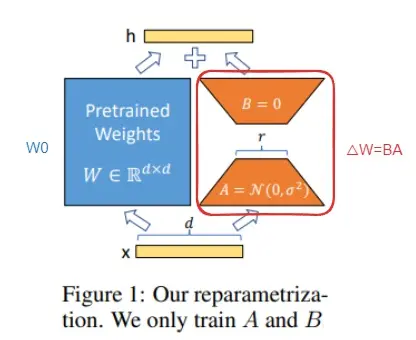
参数高效微调一般是冻结原模型,通过adapter、lora、Prefix-tuning(前缀微调)等方法微调,peft库目前已经支持这些方法,一般用lora,结构简单。
【YBH:大模型微调(finetune)方法总结-LoRA,Adapter,Prefix-tuning,P-tuning,Prompt-tuning】
lora结构如下图,只需要训练右边部分A和B,通过A降维,B升维,最终权重W = W0+△W。
全部/部分参数微调指直接在模型上训练,通过冻结模型的部分参数微调,主要有以下几种方式。
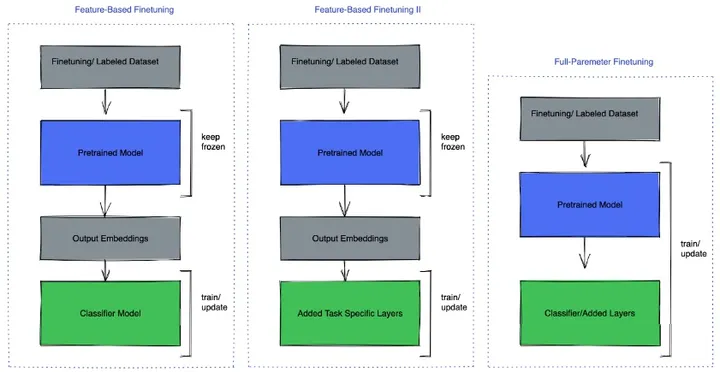
微调代码库
(1)llama2官方微调教程:llama-recipes
#if running on multi-gpu machine
export CUDA_VISIBLE_DEVICES=0
python llama_finetuning.py --use_peft --peft_method lora --quantization --model_name /patht_of_model_folder/7B --output_dir Path/to/save/PEFT/model
(3)LLaMA-Efficient-Tuning-sft监督微调
(4)Chinese-LLaMA-Alpaca-2-指令精调脚本
4.4 RLHF微调
llama2增加了RLHF(Reinforcement Learning from Human Feedback)基于人类反馈的强化学习。
RLHF训练流程如下图:
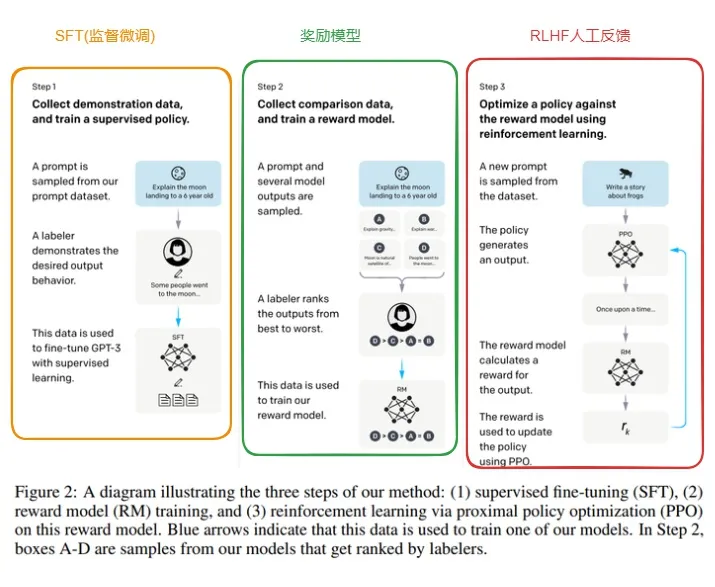
(1)先对模型进行微调,具体参考4.2微调部分。
(2)训练一个奖励模型
原则上,我们可以直接用人类标注来对模型做 RLHF 微调。然而,这将需要我们给人类发送一些样本,在每轮优化后计分,这个流程需要耗费大量人工,且需要大量数据集,而人类阅读和标注的速度有限。更简单的办法就是用用人类标注集来训练一个奖励模型。奖励模型的目的是模拟人类对文本的打分。构建奖励模型有许多能用的策略: 最直接的便是预测标注 (比如根据好与坏,输出比分或者布尔值)。最佳实践是,预测结果的排序,即对每个 prompt (输入文本) 对应的两个结果yk,yj,模型预测人类标注的比分哪个更高。
(3)基于人类反馈的强化学习
有了微调的语言模型和奖励模型,可以开始执行 RL 循环了,主要分为以下三步:
- 生成对 prompt (输入文本) 的反馈。
- 用奖励模型来对反馈评分。
- 对评分,进行一轮策略优化的强化学习。
参考链接
5. 应用
5.1 模型部署
llama2模型部署可以参考【Llama2-Chinese#-模型部署】,支持Gradio建立web端问答平台。
python examples/chat_gradio.py --model_name_or_path meta-llama/Llama-2-7b-chat
5.2 模型量化
可以参考【llama.cpp】,已经支持手机上部署。
5.3 与LangChain进行集成
以检索式问答任务为例,该任务使用LLM完成针对特定文档的自动问答,流程包括:文本读取、文本分割、文本/问题向量化、文本-问题匹配、将匹配文本作为上下文和问题组合生成对应Prompt中作为LLM的输入、生成回答。具体参考【Chinese-LLaMA-Alpaca-2#langchain_zh】
5.4 Ai-agent应用
得益于llm模型的强大能力,将llm作为大脑,ai agent可以做到根据任务目标,进行思考,分解任务,然后调用相应工具完成任务。
具体参考【ai agent应用技术介绍】
5.5 llm搭建私有知识库
llm大模型的强大能力可以让llm大模型充当智能机器人进行问答,比如作为企业的智能客服,回答一些私域的问题。
具体参考【yeyan:基于llm大模型的知识库ai问答系统调研】
5.6 多模态
将视觉、点云、视频和llm集成到一起,辅助其他下游任务,比如图像检测、分割等。
- yeyan:【vlm多模态大模型】llava解析
- yeyan:【vlm多模态大模型】minigpt-4详细解析
- yeyan:【多模态大模型】点云-语言模型3d-llm解析
- OneLLM:统一的多模态设计
6. 参考
- 【facebookresearch/llama】
- 【初识CV:Transformer模型详解(图解最完整版)】
- 【Suprit:BPE 算法原理及使用指南【深入浅出】】
- 【BPE、WordPiece和SentencePiece】
- 【Luke:深入理解NLP Subword算法:BPE、WordPiece、ULM】
- 【GitHub - taishan1994/sentencepiece_chinese_bpe: 使用sentencepiece中BPE训练中文词表】
- 【千寻:Embedding的作用】
- 【Transformer Architecture: The Positional Encoding】
- 【猛猿:Transformer学习笔记一:Positional Encoding(位置编码)】
- 【CastellanZhang:【大模型慢学】GPT起源以及GPT系列采用Decoder-only架构的原因探讨】
- 【Andy Yang:为什么现在大家都在用 MQA 和 GQA?】
- 【Taylor Wu:Transformer改进之相对位置编码(RPE)】
-
【[Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间 Scientific Spaces](https://link.zhihu.com/?target=https%3A//spaces.ac.cn/archives/8265)】 - 【suc16:LLM学习记录(五)–超简单的RoPE理解方式】
-
【[Transformer升级之路:7、长度外推性与局部注意力 - 科学空间 Scientific Spaces](https://link.zhihu.com/?target=https%3A//kexue.fm/archives/9431)】 - 【LinguaMind:浅谈LLM的长度外推】
- 【itachi:如何通俗的理解beam search?】
- 【Awesome-Chinese-LLM中文数据集】
- 【awesome-instruction-dataset】
- 【awesome-instruction-datasets】
- 【LLaMA-Efficient-Tuning-数据集】
- 【LLaMA-Efficient-Tuning】
- 【YBH:大模型微调(finetune)方法总结-LoRA,Adapter,Prefix-tuning,P-tuning,Prompt-tuning】、
- 【/facebookresearch/llama-recipes】
- 【FlagAlpha/Llama2-Chinese】
- 【ymcui/Chinese-LLaMA-Alpaca-2: 中文 LLaMA-2 & Alpaca-2 大模型二期项目】
- 【hiyouga/LLaMA-Efficient-Tuning】
- 【https://github.com/ggerganov/llama.cpp】
- 【StackLLaMA用 RLHF 训练 LLaMA 的手把手教程】
- 【llm-course:大模型课程文档】
- 【ai agent应用技术介绍】
- 【yeyuan: 一文看懂llama2(原理,模型,训练)】
- 【yeyan:基于llm大模型的知识库ai问答系统调研】