第一章 机器学习基础
1. 机器学习的概念
机器学习(Machine Learning,ML)是使用计算机来彰显数据背后的真实含义,它为了把无序的数据转换成有用的信息。是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
2. 机器学习研究的意义
机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。 “机器学习是对能通过经验自动改进的计算机算法的研究”。 “机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。” 一种经常引用的英文定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
机器学习已经有了十分广泛的应用,例如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用。
3. 机器学习算法的分类
在机器学习中,根据任务的不同,可以分为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)、半监督学习(Semi-Supervised Learning)和增强学习(Reinforcement Learning)。
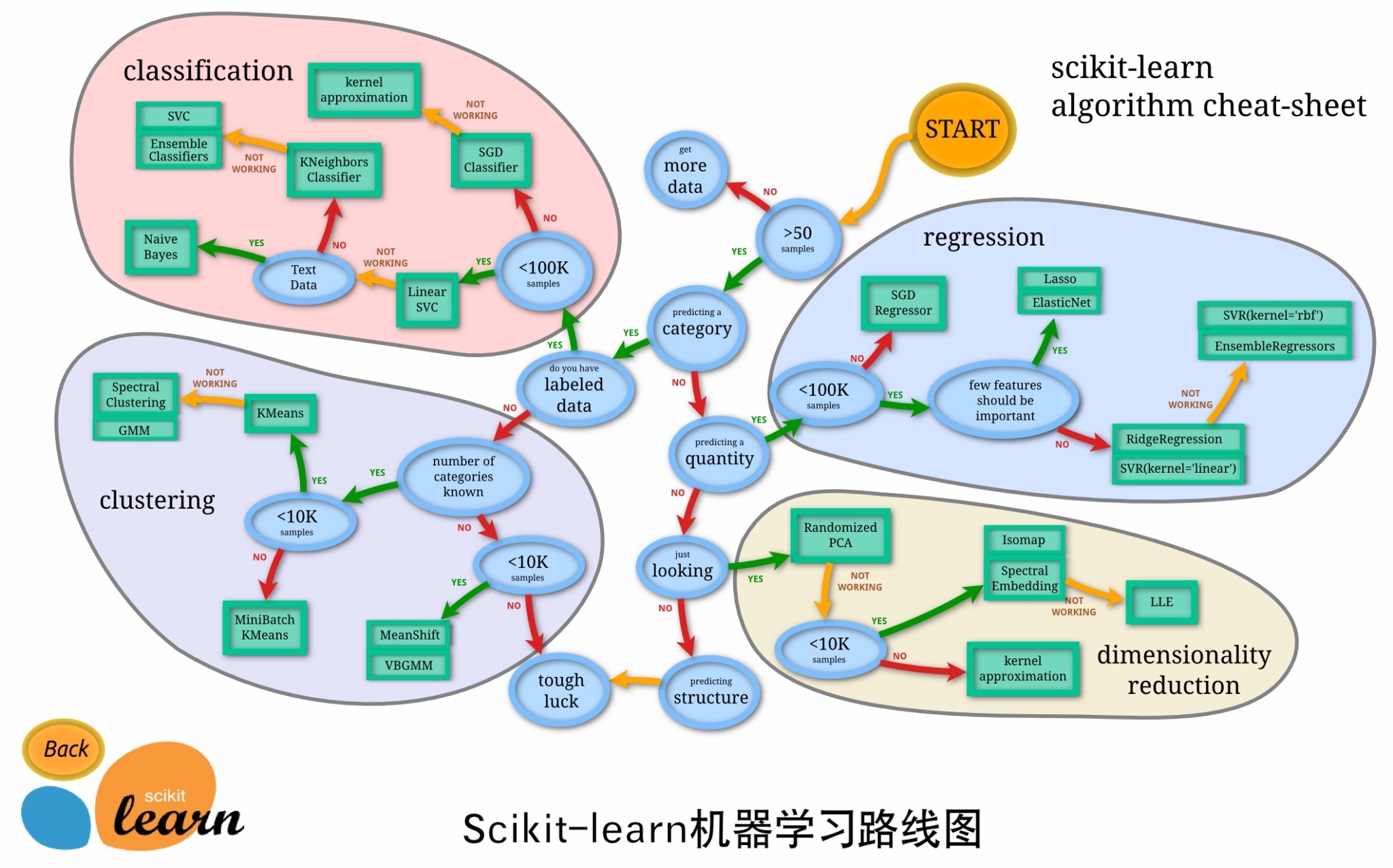
3.1 监督学习(Suervised Learning)
监督学习(Supervised Learning)的训练数据包含了类别信息,如在垃圾邮件检测中,其训练样本包含了邮件的类别信息:垃圾邮件与非垃圾邮件。机器学习中典型的问题是分类(Classification)和回归(Regression),典型的算法有Logistic Regression、BP神经网络算法和线性回归算法。
-
必须确定目标变量的值,以便机器学习算法可以发现特征和目标变量之间的关系。在监督学习中,给定一组数据,我们知道正确的输出结果应该是什么样子,并且知道在输入和输出之间有着一个特定的关系。 (包括:分类和回归)
-
样本集:训练数据 + 测试数据
-
训练样本 = 特征(feature) + 目标变量(label: 分类-离散值/回归-连续值)
-
特征通常是训练样本集的列,它们是独立测量得到的。
-
目标变量: 目标变量是机器学习预测算法的测试结果。
- 在分类算法中目标变量的类型通常是标称型(如:真与假),而在回归算法中通常是连续型(如:1~100)。
-
-
监督学习需要注意的问题:
-
偏置方差权衡
-
功能的复杂性和数量的训练数据
-
输入空间的维数
-
噪声中的输出值
-
-
知识表示:
-
采用规则集的形式【例如:西瓜每亩的产量大于5000斤为优秀】
-
采用概率分布的形式【例如:通过数据统计分析发现,某地区90%的土地西瓜亩产量,在4000斤以下,那么亩产量大于4000斤的定为优秀】
-
使用训练样本集中的一个实例【例如:通过样本集合,我们训练出一个模型实例,得出色泽鲜艳、亩产量4-5000斤、口感好等,我们认为是优秀】
-
3.2 无监督学习(Unsupervised Learning)
无监督学习(Unsupervised Learning)是另一种机器学习算法,与监督学习(Supervised Learning)不同的是,在无监督学习中,其样本中只含有特征,不包含标签信息。由于无监督学习不包含标签信息,在学习时并不知道其分类结果是否正确。
-
在机器学习中,无监督学习的问题是,在未加标签的数据中,试图找到隐藏的结构。因为提供给学习者的实例是未标记的,因此没有错误或报酬信号来评估潜在的解决方案。
-
无监督学习是密切相关的统计数据密度估计的问题。然而无监督学习还包括寻求,总结和解释数据的主要特点等诸多技术。在无监督学习使用的许多方法是基于用于处理数据的数据挖掘方法。
-
数据没有类别信息,也不会给定目标值。
-
非监督学习包括的类型:
-
聚类:在无监督学习中,将数据集分成由类似的对象组成多个类的过程称为聚类。
-
密度估计:通过样本分布的紧密程度,来估计与分组的相似性。
-
此外,无监督学习还可以减少数据特征的维度,以便我们可以使用二维或三维图形更加直观地展示数据信息。
-
3.3 强化学习(Reinforcement Learning)
强化学习(reinforcement learning),又称再励学习、评价学习,是一种重要的机器学习方法,在智能控制机器人及分析预测等领域有许多应用。
强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏,强化学习不同于连接主义学习中的监督学习,主要表现在强化信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统RLS(reinforcement learning system)如何去产生正确的动作。由于外部环境提供的信息很少,RLS必须靠自身的经历进行学习。通过这种方式,RLS在行动-评价的环境中获得知识,改进行动方案以适应环境。
3.4 半监督学习
半监督学习(Semi-Supervised Learning,SSL)是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。当使用半监督学习时,将会要求尽量少的人员来从事工作,同时,又能够带来比较高的准确性,因此,半监督学习目前正越来越受到人们的重视。
4. 机器学习训练过程
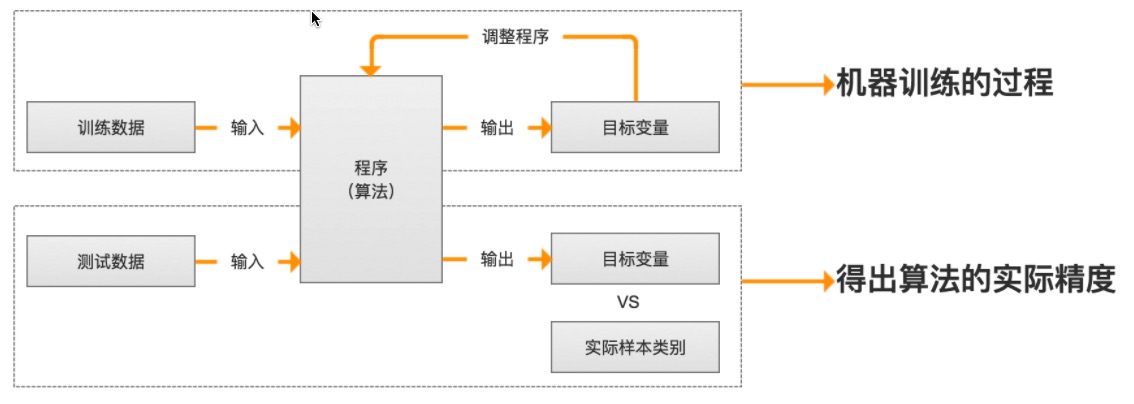
5. 机器学习常用术语
-
模型(model):计算机层面的认知
-
学习算法(learning algorithm),从数据中产生模型的方法
-
数据集(data set):一组记录的合集
-
示例(instance):对于某个对象的描述
-
样本(sample):也叫示例
-
属性(attribute):对象的某方面表现或特征
-
特征(feature):同属性
-
属性值(attribute value):属性上的取值
-
属性空间(attribute space):属性张成的空间
-
样本空间/输入空间(samplespace):同属性空间
-
特征向量(feature vector):在属性空间里每个点对应一个坐标向量,把一个示例称作特征向量
-
维数(dimensionality):描述样本参数的个数(也就是空间是几维的)
-
学习(learning)/训练(training):从数据中学得模型
-
训练数据(training data):训练过程中用到的数据
-
训练样本(training sample):训练用到的每个样本
-
训练集(training set):训练样本组成的集合
-
假设(hypothesis):学习模型对应了关于数据的某种潜在规则
-
真相(ground-truth):真正存在的潜在规律
-
学习器(learner):模型的另一种叫法,把学习算法在给定数据和参数空间的实例化
-
预测(prediction):判断一个东西的属性
-
标记(label):关于示例的结果信息,比如我是一个“好人”。
-
样例(example):拥有标记的示例
-
标记空间/输出空间(label space):所有标记的集合
-
分类(classification):预测是离散值,比如把人分为好人和坏人之类的学习任务
-
回归(regression):预测值是连续值,比如你的好人程度达到了0.9,0.6之类的
-
二分类(binary classification):只涉及两个类别的分类任务
-
正类(positive class):二分类里的一个
-
反类(negative class):二分类里的另外一个
-
多分类(multi-class classification):涉及多个类别的分类
-
测试(testing):学习到模型之后对样本进行预测的过程
-
测试样本(testing sample):被预测的样本
-
聚类(clustering):把训练集中的对象分为若干组
-
簇(cluster):每一个组叫簇
-
监督学习(supervised learning):典范–分类和回归
-
无监督学习(unsupervised learning):典范–聚类
-
未见示例(unseen instance):“新样本“,没训练过的样本
-
泛化(generalization)能力:学得的模型适用于新样本的能力
-
分布(distribution):样本空间的全体样本服从的一种规律
-
独立同分布(independent and identically distributed,简称i,i,d.):获得的每个样本都是独立地从这个分布上采样获得的。
5.1 数据集的划分
-
训练集(Training set) —— 学习样本数据集,通过匹配一些参数来建立一个模型,主要用来训练模型。类比考研前做的解题大全。
-
验证集(validation set) —— 对学习出来的模型,调整模型的参数,如在神经网络中选择隐藏单元数。验证集还用来确定网络结构或者控制模型复杂程度的参数。类比 考研之前做的模拟考试。
-
测试集(Test set) —— 测试训练好的模型的分辨能力。类比 考研。这次真的是一考定终身。
5.2 模型拟合程度
-
欠拟合(Underfitting):模型没有很好地捕捉到数据特征,不能够很好地拟合数据,对训练样本的一般性质尚未学好。类比,光看书不做题觉得自己什么都会了,上了考场才知道自己啥都不会。
-
过拟合(Overfitting):模型把训练样本学习“太好了”,可能把一些训练样本自身的特性当做了所有潜在样本都有的一般性质,导致泛化能力下降。类比,做课后题全都做对了,超纲题也都认为是考试必考题目,上了考场还是啥都不会。
5.3 常见的模型指标
-
正确率 —— 提取出的正确信息条数 / 提取出的信息条数
-
召回率 —— 提取出的正确信息条数 / 样本中的信息条数
-
F 值 —— 正确率 * 召回率 * 2 / (正确率 + 召回率)(F值即为正确率和召回率的调和平均值)
举个例子如下: 某池塘有 1400 条鲤鱼,300 只虾,300 只乌龟。现在以捕鲤鱼为目的。撒了一张网,逮住了 700 条鲤鱼,200 只 虾, 100 只乌龟。那么这些指标分别如下: 正确率 = 700 / (700 + 200 + 100) = 70% 召回率 = 700 / 1400 = 50% F 值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
5.4 模型
-
分类问题 —— 说白了就是将一些未知类别的数据分到现在已知的类别中去。比如,根据你的一些信息,判断你是高富帅,还是穷屌丝。评判分类效果好坏的三个指标就是上面介绍的三个指标:正确率,召回率,F值。
-
回归问题 —— 对数值型连续随机变量进行预测和建模的监督学习算法。回归往往会通过计算 误差(Error)来确定模型的精确性。
-
聚类问题 —— 聚类是一种无监督学习任务,该算法基于数据的内部结构寻找观察样本的自然族群(即集群)。聚类问题的标准一般基于距离:簇内距离(Intra-cluster Distance) 和 簇间距离(Inter-cluster Distance) 。簇内距离是越小越好,也就是簇内的元素越相似越好;而簇间距离越大越好,也就是说簇间(不同簇)元素越不相同越好。一般的,衡量聚类问题会给出一个结合簇内距离和簇间距离的公式。
5.5 特征工程
-
特征选择 —— 也叫特征子集选择(FSS,Feature Subset Selection)。是指从已有的 M 个特征(Feature)中选择 N 个特征使得系统的特定指标最优化,是从原始特征中选择出一些最有效特征以降低数据集维度的过程,是提高算法性能的一个重要手段,也是模式识别中关键的数据预处理步骤。
-
特征提取 —— 特征提取是计算机视觉和图像处理中的一个概念。它指的是使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征。特征提取的结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点,连续的曲线或者连续的区域。